In the last few years, collecting and storing endpoint and network security event data has become an inexpensive task for organizations of all sizes. Buying extra physical hard drives or increasing the storage capacity of a server in the cloud is now more affordable than ever. Nowadays, it is common to see organizations even trying to collect every single log available across their enterprise in case it is needed for extra context during an investigation or simply just to monitor the functionality of key applications.
This concept, of course, has benefited security analysts from a data availability perspective. However, it has also created this overwhelming stage where there is so much data that traditional SIEM capabilities are limiting the way how data can be described or analyzed.
In this post, I am excited to introduce The Hunting ELK (HELK) to the community. HELK is an ecosystem composed of several open source frameworks working together with the main goal of empowering threat hunters and extending the functionalities of an Elastic ELK stack by enabling advanced analytics capabilities. This post will shortly introduce every component of the HELK and provide a few basic use cases to explain some of the benefits that it could bring to a hunt team.
I believe that in order to understand what it is that I am trying to solve with the HELK, it is important to understand what I like and wish I had when using a basic ELK stack (SIEM).
Note: Initial basic capabilities similar to the ones used by traditional SIEMs are part of the FREE and Basic elastic subscriptions. You need to purchase the Platinum subscription if you want to start using a few similar (not necessarily better) functionalities that the HELK provides. You can read more about elastic subscriptions and all the great features that you get if you pay here.
What I Like About You!
Elasticsearch
- High scalability in data ingestion (Write) and data availability (Read)
- When I do research at home or test a few things in larger environments, I love to ingest data as fast as it is generated and make it instantly available in my stack for analysis.
- Elasticsearch has approximately a write rate of 1M+ events per second and default refresh interval of 1 second for data to be readable.
- Simple data model
- Restful API
- Custom flexible aggregations and operations via its flexible API
- Sharding
- It allows horizontal split/scale of the data
- It allows you to distribute and parallelize operations across shards (potentially on multiple nodes) thus increasing performance/throughput
Kibana
- Native real time exploration on the top of elasticsearch
- Dashboard flexibility
- Drag and drop functionalities
- Custom visualizations via Vega!
- Declarative format to make custom data visualizations
- Integration of interactive views using D3
- Multiple data sources in one graph
Logstash
- Pluggable pipeline architecture
- Integration with messaging queues technologies
- Enhancing real-time streaming
- Horizontally scalable data processing pipeline
- Great flexibility when normalizing and transforming data
- Ability to write custom Ruby scripts to manipulate data at the pipe level
- Native integration with Elasticsearch
Clearly, right out of the box, with a basic ELK stack, one can easily have a traditional SIEM up and running in a few minutes. My journey with an ELK stack started early last year, and I blogged about how to set one up. If you are interested in building your own manually, you can follow the steps here. If you are using a similar basic setup, your build might look similar to the following:
 |
| Figure 1: Basic ELK Stack design |
Now, I Wish I Had..
A Declarative Structure Language like SQL
What if you could easily run the following query on an elasticsearch database and get results right away?
“SELECT process_guid,process_name,command_line FROM sysmon WHERE event_id=1 limit 10”
 |
| Figure 2: SQL query results |
Yes, I know! You can get a similar result in Kibana ;)
 |
| Figure 3: Kibana results. similar to basic SQL query |
|
However, what if I wanted to do the following:
- WHERE the event IDs are 1 for process create and 3 for network connections
- SELECT specific fields FROM a Sysmon Index
- WHERE the destination IP addresses are specific internal IPs
- JOIN those events ON equal Process GUID values to enrich the data and get process and network information on the same record.
Yes, a simple JOIN inside of a Sysmon index. In a SQL-like query, it might look something like this:
“SELECT p.process_parent_name, p.parent_command_line, p.process_name,p.command_line, p.hash_sha1, n.dst_ip
FROM sysmon p
JOIN sysmon n ON p.process_guid = n.process_guid
WHERE p.event_id = 1 AND n.event_id = 3 AND n.dst_ip LIKE '172.%' limit 5”
 |
| Figure 4: Results of basic JOIN with a basic SQL query |
Can you do that in Kibana when working with an elasticsearch database with a flat schema? You might end up with an OR statement for event IDs 1 and 3, and the rest you can see it in the figure below. Not efficient!
 |
| Figure 5: Attempting to get the same results (SQL-like query) with Kibana |
|
That was just one JOIN query on the same index. Just imagine how it would be across several indices. Elasticsearch is document-oriented and not a structured relational database so it is hard to run even basic JOIN queries across several indices since there is not a concept of a join key. According to elastic’s Query DSL documentation, performing full SQL-style joins in a distributed system like Elasticsearch is prohibitively expensive.
One way that Elasticsearch sort of allows you to have a similar concept of a JOIN (not necessarily a SQL JOIN) is via nested documents and parent child. However, it becomes very cumbersome when one tries to use nested queries to accomplish a similar SQL-like JOIN result. You usually end up with a complex hierarchical query where you have to define the parent, the child and other information that makes the operation very inefficient.
Elasticsearch apparently is planning on releasing an Elasticsearch SQL functionality in their X-Pack 6.3 public release, but it will be available only starting with the platinum commercial subscription. If you want to learn more about Elasticsearch SQL, I recommend watching this great video by Costin Leau from elastic.
Graph Analytics Capabilities
As you already know, finding relational data patterns in an elasticsearch database is not an easy task. As shown before, one could start joining event sources and describe their relationships with the help of SQL-like queries. However, it could turn a little bit challenging defining several JOINs when the data and relationships grow tremendously (so-called join pain). Therefore, I think it would be nice to be able to describe those large data sets via graph algorithms and find structural patterns in a more intuitive way via declarative graph queries.
It is important to remember that graph analytics is not just simply collecting data and showing a graph with nodes (vertices) connected to each other via common relationships (edges). A graph is just a logical representation of the data. I have seen visual representations of graphs where there were so many vertices displayed, it was hard to even know what exactly was going on. A graph with thousands vertices all in one image with nodes on the top of each other is not useful. One needs to either filter that down or apply graph analytics to identify specific structured patterns or describe the data in a more intuitive and efficient way.
What if I had a large data set of Windows Security event logs and I wanted to identify patterns of users authenticating to other systems in the network. Searching for successful logon events type 3 (network) might be a good start. The typical analysts view would be the following:
 |
| Figure 6: Windows Security Event Logs - Logon Type 3 |
|
Even though some might say that blue teamers think in lists, I believe that it is the technology in front of them that might be limiting the way how they think about the data. One could think of the data above, from an endpoint to endpoint perspective, the following way (portion of the data):
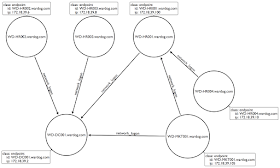 |
| Figure 7: Representing a portion of the security event logs in a graph |
However, how do you manipulate that data as a graph in kibana? In addition, it is easy to follow the figure above and count all the relationships per node. However, in a real environment, you will have so many relationships (edges) and nodes (vertices) that it could be hard to just look at a graph and make decisions from it.
Enabling graph analytics would allow security analysts to:
- Identify the relative importance of an endpoint or user based on the number of connections in comparison to other endpoints or users in the network.
- Calculate the inbound and outbound connections from each endpoint (Directed Graph)
- Group endpoints into connected subgraphs
- Detect communities of endpoints or users
- Search for structural patterns in the graph (Cypher-like Queries)
What if I wanted to describe basic structural parent-child patterns in a Sysmon process create dataset? It would be nice to be able to use Cypher-like queries like the following one:
"(a)-[]->(b);(b)-[]->(c)"
 |
| Figure 8: Results of structure parent query |
Elastic provides a few graphing functionalities, but only when you install X-Pack and purchase its Platinum subscription. You can learn more about it in the “Graphing Connections in Your Data” documentation in the Kibana User Guide. It does not provide a flexible way to apply graph algorithms or an easy declarative graph query language to define structural patterns.
Also, graphing features provided by X-pack have limited support for multiple indices. According to the Graph Limitations documentation, the Graph API can explore multiple indices, types, or aliases in a single API request, but the assumption is that each "hop" it performs is querying the same set of indices. Currently, it is not possible to take a term found in a field from one index and use that value to explore connections in a different field held in another type or index.
Machine Learning Capabilities
A new signature, a new alert, another signature, another alert, and another alert!! Yes, that is most likely what you experience at work every single day as a security analyst. You ever wonder what it would be like to go beyond just detections built to catch the specific known bad? What about learning a little bit more about other analytics techniques that could help derive insights and make predictions or recommendations based on data? Yes, I wish I could implement and explore Machine Learning (ML) concepts on top of an ELK stack.
According to Chio, Clarence; Freeman, David in “Machine Learning and Security: Protecting Systems with Data and Algorithms (Kindle Locations 282-283)”, at its core, machine learning is, “a set of mathematical techniques, implemented on computer systems, that enables a process of information mining, pattern discovery, and drawing inferences from data.”
According to Chambers, Bill; Zaharia, Matei. in “Spark: The Definitive Guide: Big Data Processing Made Simple (Kindle Locations 13051-13053)”, the best ontology for machine learning is structured based on the task that you’d like to perform. The most common tasks include:
- Supervised learning, including classification and regression, where the goal is to predict a label for each data point based on various features.
- Recommendation engines to suggest products to users based on behavior.
- Unsupervised learning, including clustering, anomaly detection, and topic modeling, where the goal is to discover structure in the data.
- Graph analytics tasks such as searching for patterns in a social network.
On May 4th, 2017, Elastic announced the first release of machine learning features for the Elastic Stack, available via X-Pack and its commercial Platinum subscription. It is important to mention that the machine learning features of X-Pack are focused only on providing “Time Series Anomaly Detection” capabilities using unsupervised machine learning. Don’t get me wrong, this is great to have!! It just would be nice to have the flexibility even when paying for a commercial license to be able to test additional ML use cases and implementations.
Streaming Processing Capabilities
Support for a declarative structured language like SQL or for new concepts such as graph analytics and ML on the top of an ELK stack would be great!!! But do you know what would be awesome? If I could also do all that, but in real time and via a distributed streaming engine.
According to Chambers, Bill and Zaharia, Matei in “Spark: The Definitive Guide: Big Data Processing Made Simple” (Kindle Locations 11049-11052), stream processing is the act of continuously incorporating new data to compute a result. In stream processing, the input data is unbounded and has no predetermined beginning or end. It simply forms a series of events that arrive at the stream processing system (e.g., credit card transactions, clicks on a website, or sensor readings from Internet of Things [IoT] devices).
Looking at our previous JOIN example, it would be awesome to stream-process similar structured queries that we used before as the data flows through the data pipeline and send the results over to an elasticsearch index.
 |
| Figure 9: Structured streaming |
 |
| Figure 10: Structured streaming results sent to Elasticsearch and visualized via Kibana |
As you can see in the images above, applying the structured transformation (SQL JOIN) to the data in real-time will make the data enrichment process a lot easier and more efficient. Some of the use cases for security analysts could include:
- Real-time decision making
- Identification of relationships and patterns in real time leads to faster detection and response
- Data updates in real time
- Data being enriched and updated in real time enables analysts to query the data faster downstream. (i.e JOINs)
- ML models updates (The most challenging use case)
- Interactive data pipelines (structured format)
- This enables analysts to query the data in a structured way before it even gets to elasticsearch
Interactive Hunt Playbooks Support
Last but not least, one aspect of threat hunting that I feel is being considered more and more in the industry is the fact that it needs structure. Specially, during a hunting engagement, knowing what it is that you are trying to hunt for allows your team to align to the business use cases, priorities and threat landscape. Therefore, I wish I had a way to document and share the methodology I would use to explore and analyze data during a hunting engagement. This would be beneficial even for security analysts that are just starting in the field. In the image below you can see an example of a playbook that a hunter could follow to expedite the time of analysis and transformation of the data.
 |
| Figure 11: Notebook Example |
Wouldn’t it be nice to have all that in one framework and in an affordable way (Open Source)?
Welcome To HELK!!!
The Hunting ELK or simply the HELK is one of the first public ELKs that enables advanced analytics capabilities for free. Every wish that I had became every reason to start building the HELK. In fact, all the examples shown throughout this post were performed with the HELK. This project was developed primarily for research, but due to its flexible design and core components, it can be deployed in larger environments with the right configurations and scalable infrastructure. Therefore, there are a variety of use cases that can be prototyped with it. The main implementation of this project is Threat Hunting (Active Defense).
Enabling Advanced Analytics
 |
| Figure 12: HELK advanced analytics frameworks |
Core Components Definitions
Kafka
"Kafka is a distributed publish-subscribe messaging system used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies." Apache Kafka
Elasticsearch
"Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements." Elastic
Logstash
"Logstash is an open source data collection engine with real-time pipelining capabilities. Logstash can dynamically unify data from disparate sources and normalize the data into destinations of your choice. Cleanse and democratize all your data for diverse advanced downstream analytics and visualization use cases.” Elastic
Kibana
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps. Kibana makes it easy to understand large volumes of data. Its simple, browser-based interface enables you to quickly create and share dynamic dashboards that display changes to Elasticsearch queries in real time." Elastic
Apache Spark
"Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming." Apache Spark
ES-Hadoop
"Elasticsearch for Apache Hadoop is an open-source, stand-alone, self-contained, small library that allows Hadoop jobs (whether using Map/Reduce or libraries built upon it such as Hive, Pig or Cascading or new upcoming libraries like Apache Spark ) to interact with Elasticsearch. One can think of it as a connector that allows data to flow bi-directionally so that applications can leverage transparently the Elasticsearch engine capabilities to significantly enrich their capabilities and increase the performance." Elastic
GraphFrames
"GraphFrames is a package for Apache Spark which provides DataFrame-based Graphs. It provides high-level APIs in Scala, Java, and Python. It aims to provide both the functionality of GraphX and extended functionality taking advantage of Spark DataFrames. This extended functionality includes motif finding, DataFrame-based serialization, and highly expressive graph queries." GraphFrames
Jupyter Notebook (JupyterLab)
"The Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, data visualization, machine learning, and much more." Jupyter
Design
The figure above is pretty straightforward and shows you how each piece is connected. However, I think it is important to provide some more context around the connections:
- Data gets collected with Winlogbeats (Only shipper supported for now)
- I encourage you to use WEF servers to aggregate all your Windows logs and then use winlogbeats to ship the logs to Kafka
- Kafka stores event logs on specific topics and publish them to anyone who subscribe to them
- There are two applications that can subscribe to Kafka topics
- Logstash subscribes to specific topics available in Kafka. It collects every single log available in the Kafka brokers
- Spark also has the capability to subscribe to specific Kafka topics, but it uses them to apply other advanced analytics not available in Logstash. Structured streaming is possible with Spark and Kafka.
- Logstash sends data to Elasticsearch
- Data gets visualized via Kibana
- ES-Hadoop allows Spark to communicate with Elasticsearch
- Jupyter Lab Notebook is the default Python Driver for Pyspark (Spark’s Python Language API). Therefore, every notebook created in Jupyter will automatically have the option to use Spark Python language APIs. There are other languages available such as Scala and SQL.
- Graphframes can be imported via Pyspark and Scala in Jupyter
Current Status
The project is currently in an alpha stage, which means that the code and the functionality are still changing. We haven't yet tested the system with large data sources and in many scenarios. We invite you to try it and welcome any feedback.
Getting Started
You can start playing with the HELK in a few steps:
HELK Download
- git clone https://github.com/Cyb3rWard0g/HELK.git
HELK Install
- cd HELK/
- sudo ./helk_install.sh
For more details, visit the HELK’s Wiki on GitHub.
Contributing
I would love to make the HELK a more stable build for everyone in the community. If you are interested on helping me accomplish that, and adding some other great capabilities to it, PLEASE feel free to submit a pull request.
GitHub Link: https://github.com/Cyb3rWard0g/HELK
This is all for today! This was just an introduction to the HELK. I tried to keep it as simple as possible in order to cover most of its capabilities in basic terms. In the following posts, I will be expanding a lot more on the technical details of each component and showing a few use cases via Jupyter Notebooks so that you can try them at home too. I am also learning while in the process of developing the HELK, so I would really appreciate your feedback!!


























